Слияние списка и стражей
(Этот раздел описывает улучшенную оптимизацию и может быть опущен при первом чтении.)
Пример связного списка со стражами может быть улучшен благодаря еще одной оптимизации, которая реально используется в последней версии библиотек ISE. Мы бегло ее рассмотрим, поскольку она достаточно специфична и не носит общего характера. Такие оптимизации, тщательно выполняемые, должны осуществляться только для широко используемых компонентов повторного использования. Другими словами, они не для домашних разработок.
Можно ли получить преимущества от стражей без соответствующих потерь памяти? При рассмотрении их концепции отмечалось, что их можно рассматривать фиктивно, но тогда мы потеряем критически важную оптимизацию, позволившую нам написать тело forth следующим образом:
index := index + 1 previous := active active := active.rightбез дорогих проверок предыдущей версии. Мы избежали тестов, будучи уверенными, что active не равно Void, когда список не находится в состоянии after. Это следствие утверждения инварианта (active = Void) = after; верного потому, что у нас есть настоящее звено - страж, доступный как active, даже если список пуст.
Для других программ, отличных от forth, оптимизация не столь существенна. Но forth, как отмечалось, - насущная потребность, "хлеб и масло" клиентов, обрабатывающих списки. Из-за последовательной природы списков типичное использование имеет вид:
from your_list.start until your_list.after loop ...; your_list.forth endНет ничего необычного, если при построении профиля, измеряя, как выполняются вычисления, вы обнаружите, что большая доля времени приходится на работу forth. Так что стоило заплатить за ее оптимизацию, поскольку она обеспечивает кардинальное улучшение производительности, будучи свободной от тестов.
За выигрыш во времени мы заплатили, как обычно, проигрышем в памяти, - теперь каждый список имеет дополнительный элемент, не хранящий информации. Это кажется проблемой лишь в случае большого числа коротких списков, иначе относительные потери несущественны.
Но могут возникнуть более серьезные проблемы:
- Во многих случаях, как упоминалось, могут понадобиться двунаправленные списки, полностью симметричные с элементами класса BI_LINKABLE , имеющие ссылки на левого и правого соседа. Класс TWO_WAY_LIST (который, кстати, может быть написан как дважды наследуемый от LINKED_LIST, основываясь на технике дублируемого наследования) будет нуждаться как в левом, так и правом страже.
- Связные деревья (см. лекцию 15 курса "Основы объектно-ориентированного программирования") представляют более серьезную проблему. Практически важным является класс TWO_WAY_TREE, задающий удобное представление деревьев с двумя ссылками (на родителя и потомка). Построенный на идеях, описываемых при представлении множественного наследования, класс объединяет понятия узла и дерева, так что он является наследником TWO_WAY_LIST и BI_LINKABLE. Но тогда каждый узел является списком, может быть двунаправленным и хранить обоих стражей.
Для нахождения решения зададимся неожиданным вопросом.
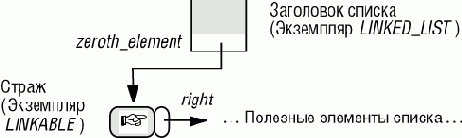
Рис. 5.12. Заголовок и страж
В нашей структуре нужны ли действительно два объекта, занимающиеся учетом? По настоящему полезная информация находится в фактических элементах списка, не показанных на рисунке. Для управления ими мы добавили заголовок списка и страж - двух стражей для двунаправленного списка. Для длинных списков можно игнорировать эту раздутую структуру учета, подобно большой компании, содержащую много сотрудников среднего звена во времена процветания, но в тяжелые времена, объединяющую функции управления.
Можем ли мы заставить заголовок списка играть роль стража? Оказывается, можем. Все, что имеет LINKABLE - это поле item и ссылку right. Для стража необходима только ссылка, указывающая на первый элемент, так что, если поместить ее в заголовок, то она будет играть ту же роль, как когда она называлась first_element в первом варианте со стражами.
Проблема, конечно, была в том, что first_element мог иметь значение void для пустого списка, что принуждало во все алгоритмы встраивать тесты в форме if before then ... Мы точно не хотим возвращаться назад к этой ситуации. Но можем использовать концептуальную модель, показанную на рисунке, избавленную от стража

Рис. 5.13. Заголовок как страж (на непустом списке)
Концептуально решение является тем же самым, что и прошлое, с заменой zeroth_element ссылкой на сам заголовок списка. Для представления того, что ранее было zeroth_element.right, теперь используется first_element.

Рис. 5.14. Заголовок как страж (на пустом списке)
На пустом списке следует присоединить first_element к самому заголовку. Таким образом, first_element никогда не будет void - критическая цель, сохраняющая ситуацию простой. Осталось лишь выполнить правильные замены.
Сохраним все желательные утверждения инварианта предыдущей версии со стражами:
previous /= Void (active = Void) = after; (active = previous) = before (not before) implies (previous.right = active) is_last = ((active /= Void) and then (active.right = Void))Предложения, включающие ранее zeroth_element:
zeroth_element /= Void empty = (zeroth_elemenеt.right = Void) (previous = zeroth_element) = (before or is_first)теперь будут иметь вид:
first_element /= Void empty = (first_element = Current) (previous = Current) = (before or is_first)Но чтобы все получилось так просто, необходимо (нас ждут опасные вещи, поэтому пристегните ремни) сделать LINKED_LIST наследником LINKABLE:
class LINKED_LIST [G] inherit LINKABLE [G] rename right as first_element, put_right as set_first_element end ...Остальное в классе остается как ранее с выше показанной заменой zeroth_element...Не нонсенс ли это - позволить LINKED_LIST быть наследником LINKABLE? Совсем нет! Вся идея в том, чтобы слить воедино два понятия заголовка списка и стража, другими словами рассматривать заголовок списка как элемент списка. Поэтому мы имеем прекрасный пример отношения "is-a" ("является") при наследовании.
Мы решили рассматривать каждый LINKED_LIST как LINKABLE, поэтому наследование вполне подходит. Заметьте, отношение "быть клиентом" даже не участвует в соревновании - не только потому, что оно не подходит по сути, но оно добавляет лишние поля к нашим объектам!
Убедитесь, что ваши ремни безопасности все еще застегнуты, - мы начинаем рассматривать, что происходит в наследуемой структуре. Класс BI_LINKABLE дважды наследован от LINKABLE. Класс TWO_WAY_LIST наследован от LINKED_LIST (один раз или, возможно, дважды в зависимости от выбранной техники наследования) и, в соответствии с рассматриваемой техникой, от BI_LINKABLE. Со всем этим повторным наследованием каждый может подумать, что вещи вышли из-под контроля и наша структура содержит все виды ненужных полей. Но нет, правила разделения и репликации при дублируемом наследовании позволяют нам получить то, что мы хотим.
Последний шаг - класс TWO_WAY_TREE, по разумным причинам наследуемый от TWO_WAY_LIST и BI_LINKABLE. Достаточно для небольшого сердечного приступа, но нет - все прекрасно сложилось в нужном порядке и в нужном месте. Мы получили все необходимые компоненты, ненужных компонентов нет, концептуально все стражи на месте, так что forth, back и все связанные с ними циклы выполняются быстро, как это требуется, и стражи совсем не занимают памяти.
Это схема реально применяется ко всем действующим классам библиотеки Base. Прежде чем закончить наш полет, еще несколько наблюдений:
- Ни при каких обстоятельствах не следует выполнять работу такого вида, включающую трюки с манипуляцией структурой данных, без использования преимуществ, обеспечиваемых утверждениями. Просто невозможно обеспечить правильную работу, не установив точные утверждения инварианта и проверки совместимости.
- Механизмы дублируемого наследования являются основой (см. лекцию 15 курса "Основы объектно-ориентированного программирования"). Без методов, введенных нотацией этой книги, позволяющих дублируемым потомкам добиваться разделения или покомпонентной репликации, основываясь на простом критерии имен, невозможно эффективно описать любую ситуацию с серьезным использованием дублируемого наследования.
- Повторим наиболее важный комментарий: такие оптимизации, требующие крайней осторожности, имеют смысл только в общецелевых библиотеках, предназначенных для широкого повторного использования.В обычных ситуациях они стоят слишком дорого. Это обсуждение включено с целью дать читателю почувствовать, какие усилия требуются для разработки профессиональных компонентов от начала и до конца. К счастью, большинство разработчиков не должны прилагать столько усилий в своей работе.
